Fundamentos para mejorar el rendimiento y la eficiencia de tus modelos de Deep Learning
Todos hemos oído hablar de los famosos dispositivos IoT. A menudo, oímos todo lo que nos ofrecen, versatilidad, fácil integración en la gran mayoría de escenarios empresariales, capacidad de captación y envío de datos de forma rápida y automática…etc. Pero por otro lado, normalmente presentan características o condiciones bastantes limitadas, como por ejemplo, memoria o potencia de computo.
Cada vez mas en el mundo profesional se están llevando acabo proyectos los cuales se están integrando dichas tecnologías y mecanismos de IoT. Como por ejemplo, detección de objetos en un entorno determinado, mantenimiento predictivo de alguna maquinaria especifica, reconocimiento de acciones en personas y objetos, monitorización de áreas de trafico, reconocimiento facial… etc.
En todos estos proyectos de IoT se están exigiendo, entre muchos requisitos, que los modelos desarrollados tengan una precisión alta a la ahora de clasificar o predecir unos determinados objetivos y que al mismo tiempo tengan velocidad de respuesta o velocidad de inferencia alta (latencia). Para ello, se pueden aplicar varias optimizaciones a los modelos para que puedan ejecutarse dentro de estas restricciones que tienes los dispositivos IoT. Optimizando nuestros modelos podremos hacer uso de estos en un gran abanico de hardware, acelerando el proceso de inferencia para cumplir entre otros muchos casos, soluciones que cumplan con el procesamiento en tiempo real.
¿Por que surge todo esto de la «cuantizacion» o aceleracion de los procesos de inferencia?

Estamos llegando a la etapa de «hacer eficiente» nuestros modelos de Machine Learning y Deep Learning. Durante mucho tiempo los desarrolladores/investigadores del ámbito de la IA han estado atrapados durante muchas décadas en etapas donde la velocidad y la eficiencia no eran tan importantes como hacer que las cosas funcionen en primer lugar. Por lo tanto, la pregunta de cuán precisos y rápidos deben ser nuestros cálculos, y si podemos manejarlos con menor precisión, no era frecuente.
Resulta que después de varias investigaciones de los grupos de investigación de Microsoft, Google, Amazon..etc las DNN (Deep Neural Networks) pueden funcionar con tipos de datos más pequeños y con menor precisión, como los enteros de 8 bits. Hablando en términos generales, los números se cuantifican (es decir, se discretizan) a algunos valores específicos, que luego podemos representar usando números enteros en lugar de números de coma flotante. Por lo tanto para ser más precisos, utilizaremos una representación de punto fijo de 8 bits.
¿De que me sirve cuantizar o optimizar mis modelos?

Acelerar el proceso de inferencia utilizando técnicas de cuantización o discreticación de los cálculos numéricos de nuestras redes neuronales requiere que elaboremos partes significativas del diseño de la red, así como que volvamos a implementar la mayoría de las capas entre otros muchos cambios. Nadie va querer realizar estos procesos sin justificación alguna y sin ver cuan importantes son los resultados de optimizar nuestros modelos.
Sin embargo, hay varias razones que hacen que las ganancias valgan la pena. En primer lugar, la aritmética con menor nivel de precisión de bits es más rápida. Aunque, el cálculo de punto flotante ya no es «más lento» que el entero en las CPU modernas, las operaciones con punto flotante de 32 bits casi siempre serán más lentas que, por ejemplo, los enteros de 8 bits.
Al pasar de 32 bits a 8 bits, obtenemos (casi) una reducción de 4x en la memoria de inmediato. Los modelos más livianos significan que ocupan menos espacio de almacenamiento, son más fáciles de compartir en anchos de banda más pequeños, más fáciles de actualizar, etc. Por lo tanto, significa que podemos exprimir más datos en cachés/registros y además podemos reducir la frecuencia con la que accedemos a las cosas desde la RAM, que generalmente consume mucho tiempo y energía por parte de nuestras redes neuronales.
La aritmética de coma flotante es mas compleja que la entera, por lo que es posible que no siempre sea compatible con microcontroladores en algunos dispositivos integrados de muy baja potencia, como drones, relojes inteligentes o dispositivos IoT. El soporte entero, por otro lado, tiene una disponibilidad mas alta en los dispositivos mencionados anteriormente.
¿Que beneficios obtengo al optimizar?

Hay varias formas en que la optimización del modelo puede ayudar con el desarrollo de aplicaciones como por ejemplo uno de los principales casos es para la reducción del tamaño de nuestros modelos. Algunas formas de optimización pueden usarse para reducir el tamaño de un modelo. Los modelos optimizados obtienen los siguientes beneficios:
Tamaño de almacenamiento más pequeño: los modelos más pequeños ocupan menos espacio de almacenamiento en los dispositivos de sus usuarios. Por ejemplo, una aplicación de Android o iOS que usa un modelo más pequeño ocupará menos espacio de almacenamiento en el dispositivo móvil de un usuario.
Tamaño de descarga más pequeño: los modelos más pequeños requieren menos tiempo y ancho de banda para descargar a los dispositivos de los usuarios.
Menos uso de memoria: los modelos más pequeños usan menos RAM cuando se ejecutan, lo que libera memoria para otras partes de su aplicación y puede traducirse en un mejor rendimiento y estabilidad. La cuantización puede reducir el tamaño de un modelo en todos estos casos, potencialmente a expensas de cierta precisión. La optimización del modelo puede reducir el tamaño de este, haciendo mas comprimible y más fácilmente descargable.
Reducción de latencia: La latencia es la cantidad de tiempo que lleva ejecutar una sola inferencia con un modelo determinado. Algunas formas de optimización pueden reducir la cantidad de cómputo requerida para ejecutar la inferencia usando un modelo, lo que resulta en una latencia más baja. La latencia también puede tener un impacto en el consumo de energía. Actualmente, la cuantización puede usarse para reducir la latencia al simplificar los cálculos que ocurren durante la inferencia, potencialmente a expensas de cierta precisión.
Compatibilidad con aceleradores: Algunos hardware se comportan como aceleradores de estos procesos de inferencia, como el Edge TPU. Este tipo de microcontrolador pueden ejecutar inferencias extremadamente rápido con modelos que se han optimizado correctamente. En general, estos tipos de dispositivos requieren que los modelos se cuantifiquen de una manera específica.
Tipos de optimizaciones
Actualmente se admite la optimización de modelos mediante procesos de cuantización y «pruning«.
Cuantización

La cuantización trata de reducir la precisión de los números utilizados para representar los parámetros de un modelo, que por defecto son números de coma flotante de 32 bits. Esto da como resultado un tamaño de modelo más pequeño y un cálculo más rápido. Para realizar este tipo de optimización de nuestros modelos tendremos que entender los distintos tipos de técnicas de cuantización existentes hasta el momento.
| Tecnica | Datos | Reduccion de tamaño | Precision | Hardware soportado |
| Post-training quantization | No | Mas del 50% | Perdida de precision insignificante | CPU, GPU |
| Post-training dynamic range quantization | No | Mas del 50% | Perdida de precision | CPU |
| Post-training integer quantization | Muestra representativa no etiquetada | Mas del 75% | Perdida pequeña de precision | CPU, EdgeTPU |
| Quantization-aware training | Datos de entrenamiento etiquetados | Mas del 75% | La perdida de precision mas pequeña de todas | CPU, EdgeTPU |
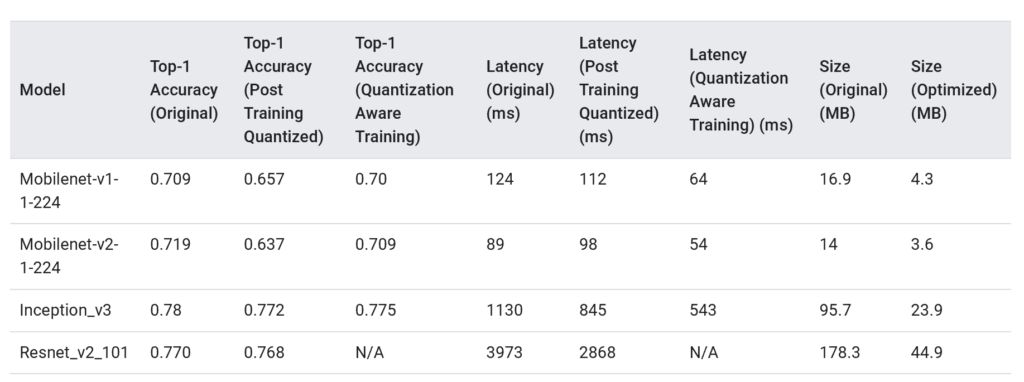
A continuación se muestran los resultados de latencia y precisión para post-training quantization y quantization-aware training en algunos modelos, ya que son dos de las técnicas mas utilizadas. Todos los números de latencia se han medido en dispositivos móviles que usan una sola CPU.
Pruning

El pruning funciona eliminando parámetros dentro de un modelo que tienen poco impacto en las predicciones. Los modelos en los que se han hecho «pruning» son del mismo tamaño en el disco y tienen la misma latencia de tiempo de ejecución, pero se pueden comprimir de manera más efectiva. Esto hace que el «pruning» sea una técnica útil para reducir el tamaño de descarga del modelo.
¿Que librerias existen actualmente para realizar estas optimizaciones?

Después de haber comentado los beneficios y porque es importante realizar estos procesos de optimización, puede ver por qué todo esto es como una «gran noticia o avance» para alguien interesado en aplicaciones de Deep Learning o Machine Learning y que desea integrar sus modelos en dispositivos móviles o IoT. Los investigadores de Deep Learning ahora han encontrado formas de entrenar modelos que funcionan mejor con la cuantización, los desarrolladores de Machine Learning y Deep Learning al mismo tiempo están construyendo y dando soporte a una gran variedad de frameworks para mejorar los procesos de inferencia.
Los gigantes tecnológicos están poniendo su peso para conseguir cada vez mas hardware dedicado para IA, con énfasis en el soporte tanto de procesos de cuantización/optimización de procesos de inferencia como también de procesos de entrenamientos/reentrenamientos en dispositivos cada vez mas pequeños. Por lo tanto, es un campo que esta en constante actualización e investigación. Hoy en día podemos encontrarnos con varias librerías especializadas para la optimización de nuestros modelos de Deep Learning:
- TF-Lite
- TensorRT
- PyTorch Quantization (Experimental)
Conclusiones
Para terminar, voy a comentar varios puntos que deberíamos hacer una vez que terminemos de leer este post.
- Verifica si tus modelos necesitan optimizarse, comienza utilizando la técnica de post-training quantization, ya que esto es ampliamente aplicable y no requiere datos de entrenamiento.
- Para los casos en que tus modelos no cumplan los objetivos de precisión y latencia, o si el soporte del acelerador de hardware es importante como un uso de TPU o GPU, la mejor opción es la quantization-aware training.
- Si solo ves que hace falta únicamente reducir aún más el tamaño de tu modelo, intenta el método de «pruning» antes de cuantificar los modelos.
Por si ha quedado alguna duda, os dejo el link a mi repositorio (próximos días estara abierto!) donde tendréis demostraciones con las librerías de TF-Lite y TF-TRT a modo de notebooks. Además, se explican las técnicas de optimización de modelos con mucho mas detalle y paso a paso. Este post ha sido escrito principalmente para explicar a modo ilustrativo el estado del arte de los procesos de optimización de modelos actuales.