


¿Pero que es Azure Databricks?
Azure Databricks es un servicio de datos en la nube de Microsoft para implementar, compartir y mantener soluciones de datos de nivel empresarial a gran escala. Con Azure Databricks podemos procesar, almacenar, limpiar, compartir, analizar, modelar y monetizar nuestros conjuntos de datos con soluciones desde BI al aprendizaje automático.
¿Qué hay bajo las hojas de Azure Databricks?
La implementación predeterminada de Azure Databricks es la de un servicio completamente gestionado o administrado en Azure, formado por un plano de control y un plano de datos. Una arquitectura de alto nivel podría ser la siguiente:

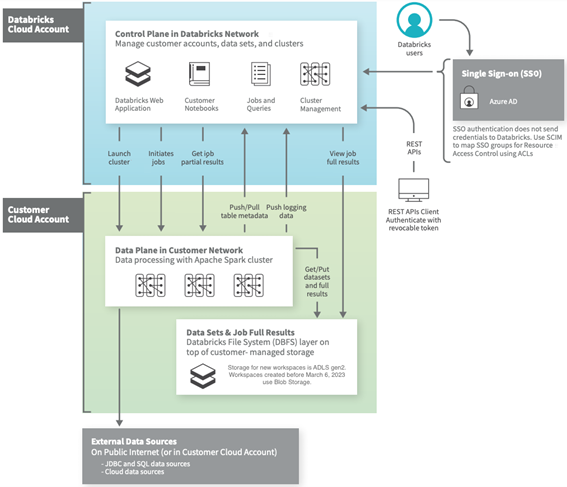
El plano de control incluye los servicios backend que Azure Databricks administra en su propia cuenta de Azure. Los “Notebooks” así como muchas otras configuraciones del espacio de trabajo son almacenadas en el plano de control y encriptadas en reposo.
En cuanto al plano de datos, es donde residen los datos y además donde los datos son procesados. Azure Databricks usa conectores para conectar los clústeres de procesamiento a fuentes de datos externas de Azure para la ingesta de datos o para el almacenamiento.
Por tanto, vemos que los datos son almacenados en una cuenta de Azure del plano de datos y en sus propios orígenes, nunca en el plano de control y es aquí donde empieza todo.
¿Qué es lo que me interesa proteger?
Por lo que hemos visto hasta el momento, las configuraciones del plano de control son almacenadas en una cuenta propia de Azure que permanece encriptada, al fin y al cabo, no dejan de ser configuraciones y scripts escritos en Python u otros lenguajes que son ejecutados a través de Notebooks.
Sin embargo y aunque el plano de datos junto a la infraestructura de procesamiento de estos, en un modo de despliegue por defecto, podría ser suficiente, muchos usuarios buscan más control sobre los servicios de configuración de red para cumplir con directivas de gobierno internas, adherirse a regulaciones externas o incluso llevar a cabo personalizaciones de dicha red, tales como conectar el cluster de nodos a otros servicios de datos de Azure de una manera segura usando Azure Service Endpoints, restringir el tráfico saliente desde el clúster, utilizar un DNS personalizado, etc.
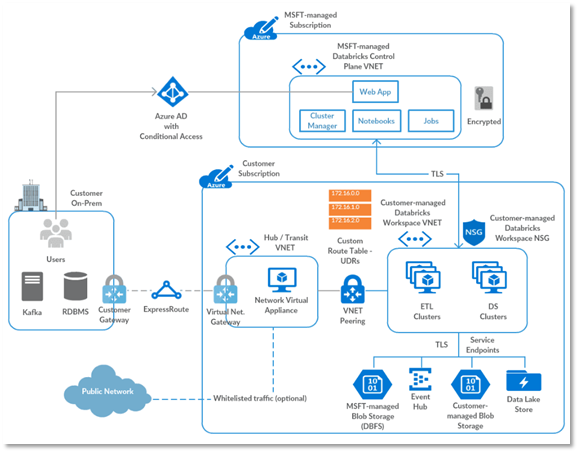
Esta característica llamada “Bring Your Own Vnet” (también llamada VNET injection):

Junto con la implementación de otra característica llamada conectividad de clúster seguro (No Public IP: NPIP):

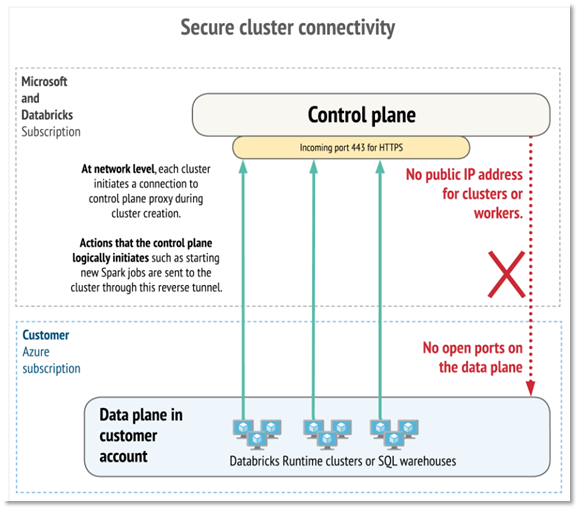
En definitiva, nos proporcionan herramientas para, por un lado, asegurar el despliegue de nuestros recursos de Azure Databricks y por otro, tener un mayor control de los servicios de red de nuestros clústeres, de manera que podamos seguir utilizando los endpoints privados para las interconexiones de dichos clústeres con otros recursos de Azure, eludiendo la utilización de los endpoints públicos y evitando que el tráfico de red escape de nuestro control a través de internet.
¿Entonces, cómo armo dicha infraestructura segura?
Un ejemplo típico de infraestructura de Azure Databricks podría ser la siguiente:

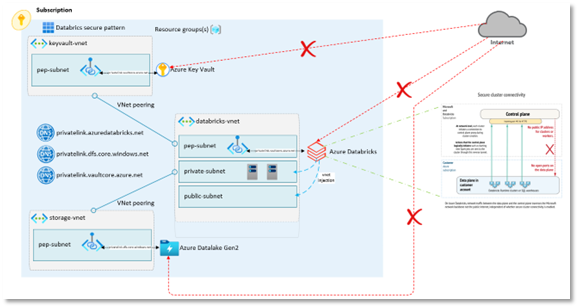
En dicha infraestructura, podemos observar un recurso de Azure Databricks Premium donde hemos utilizado conectividad de clúster segura y VNET Injection. Databricks tiene montada una cuenta de Azure Datalake Gen 2 en su Workspace donde puede acceder a los datos para su procesamiento de una manera segura y directa.
Como vemos, en ningún momento utilizamos los endpoints públicos de ningún recurso, en su lugar, utilizamos private endpoints y Azure DNS privados donde registramos dichos private endpoints. Por tanto, el tráfico de red queda contenido dentro de nuestras propias redes virtuales.
En este caso, utilizamos una topología de «interconexionado» de red interspoke a través de emparejamientos de red, aunque también cabe la posibilidad de utilizar una topología de Hub and Spoke, en el caso de que quisiéramos controlar/monitorizar el tráfico de red entre los diferentes recursos que componen la arquitectura.